


The best machine learning ideas, strategies, and plans will not succeed until you have the right team in place.
I've built and worked with many teams across disciplines, industry verticals, and companies. In this post, I will share what I've learned about the required skill sets, hiring strategies, training advice, and organizational structures that lay the foundation for a strong team.
With the vast differences between organizations, there is no golden set of rules that will always apply across the board. That being said, these are tried and true practices that will hold up in the majority of cases, and they can serve as a foundation for you to build on.
The skills you'll need on your team
In addition to the standard skillset required for software development, machine learning requires a whole new spectrum of skills. These include hard-science theoretical knowledge, data engineering, scientific programming, and business acumen.
Unfortunately for us, there is no one ideal candidate who can cover the whole spectrum alone. Thus, success hinges on your ability to balance the team with complimentary strengths and skills.

Here are some common job titles you'd look for in a machine learning team:
- Data scientist
- Machine learning engineer
- Machine learning scientist
- Statistician
- Applied researcher
- Data analyst
In addition to those newer job descriptions, you would also need to complete the crew with other more traditional engineering profiles:
- Solutions architect
- Software engineer
- Data engineer
- DevOps
- System administrator
- IT security
You’re probably thinking, “that sounds like a lot, how can we find and hire all of those specialists?”
In truth, you probably will not find them all, at least not right away. Which is why I also recommend hiring people who fit the description of “jack of all trades, master of some.” In other words, specialists who are capable and willing to cover the gaps accross some of those roles (something you see a lot of in start up and SMB culture across various departments).
“A ML team striving for excellence requires outstanding members in at least one skill and over time they should catch up with the remaining.”
Balancing skills across the team
Here are the six dimensions that I recommend you use to evaluate hiring candidates and building a machine learning team:
- Domain Knowledge
- Statistics & Probability
- Machine Learning
- Software Development
- Data Engineering
- DevOps & Cloud Architectures
At Helixa, we put our technology at the forefront of everything we do. So much so that a little less than half the company is composed of our tech team, including teams dedicated entirely to our AI and Machine Learning strategies. Our rule of thumb for hiring candidates is to find people whose strengths exceed our current team’s level of expertise on at least one dimension.
This gives us the opportunity to learn from them and elevate the average knowledge level of the team in that area. We also make sure they are willing to learn and invest in filling the skill gaps.
Here is an example of a team of new hires that balance one another quite nicely. With training, we will improve areas of weaknesses and elevate the area of expertise even further.
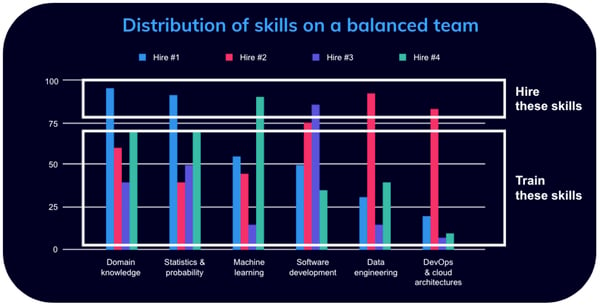
Domain knowledge is power
You may have noticed we placed domain knowledge as the first dimension in the evaluation criteria.
Data science requires an in-depth understanding of the business and the context that surrounds it. Having the right domain knowledge makes a huge difference. It allows you to approach the data knowing what you’re looking for, instead of conducting blind experiments.
The importance of domain knowledge can be summarized in the story of the ship repairman.
Here’s a paraphrased version of the story:
A shipping company hired an engineer to fix a ship engine. The engineer had all the tools in his toolkit. After some analysis the engineer took out a hammer and hit one of the components of the engine.
The engine started to work. Next day the engineer sent the invoice to the shipping company for a whopping $10,000 for hardly a five-minute job:
Hitting with Hammer — $ 2
Knowing where to Hit — $ 9,998

This story highlights the time and effort that you can save when someone on your team knows exactly where to tap with their proverbial hammer. And who has more knowledge of your business and industry than your existing team?
In The Future of Jobs report published by the World Economic Forum in 2018, they discovered that by 2022, no less than 54% of all employees will require significant training to learn new skills or upgrade their current skill set.
This begs the question: Why not train them in high-demand areas like data science and machine learning?
Don't neglect the "side" skills
There are some other, often- overlooked aspects of a successful machine learning team. Effective communication is key, for example, and maintaining the right attitude is just as important.
Storytelling with data
Storytelling may not seem immediately relevant to the machine learning process, but it’s actually critical. The primary responsibility of a data science team is to provide insights to business stakeholders, to help them make more informed decisions.
To really shine in this aspect of the job, you need to have the right business acumen and the ability to weave stories with the data in a clear and compelling way. Not everyone has this skill fully developed out of the gate, but the ability to effectively communicate and work across teams is a good start. For further reading on this topic, I would recommend checking out Storytelling with Data by Cole Nussbaumer Knaflic.
R&D&Ops
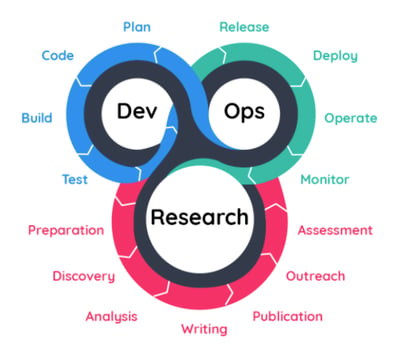
Additionally, I believe that every member of a high-performing machine learning team should feel comfortable to work in research and DevOps. This requires an open-minded attitude, as it can be quite the undertaking for those who are used to working in a single function.
I like to describe this process with the acronym R&D&Ops, which stands for Research & Development & Operations.
In companies where members of the team are singularly focused on either aspect, you would see engineers running data analysis and researching mathematical solutions while scientists write production-quality code and deploy their models.
I believe that bringing those two pieces together creates a cooperative environment that moves the team’s goals forward more efficiently. Follow these links to learn more about the research workflow and DevOps.
Choosing an effective organizational structure
When you’re assessing the organizational structure of your machine learning team, the discussion can often unearth more questions than answers.
Should data science be part of IT? Is the team linked to our existing business intelligence department? Maybe it fits better within R&D?
Some companies create their own department for data science and analytics, while others would set the team apart and call it AI, digital, engineering, or any other related word. Some larger corporations may even choose to incorporate independent machine learning teams within each business unit.
The possibilities go on and on.
But instead of attempting to address every possible combination, I think it's more efficient to start with a baseline organizational structure that you can implement as you build your machine learning team.
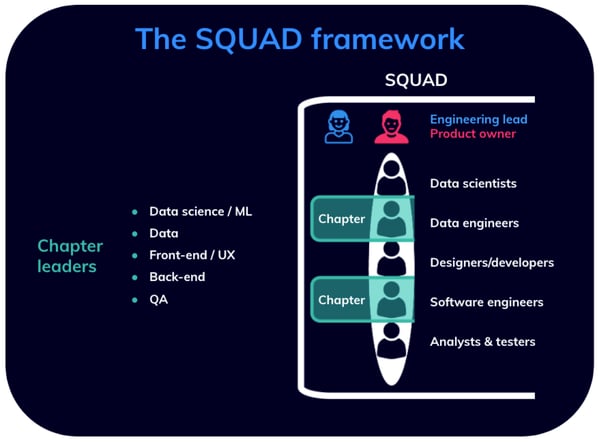
The squad framework
In the example of Spotify’s squad framework, you would have people from different functions (the "chapters") gathered together in cross-functional teams that develop features (the "squads"). The squads are fully autonomous and own the end-to-end responsibility for what they build.
The environment for the squad would be created and maintained by the department’s engineering leader, while the product owners mediate with stakeholders and set squad priorities. Chapter leads, on the other hand, would behave as line managers for members of the same chapter while also working as part of a squad and participating in day-to-day activities.
Scaling the squad framework
What I like about this approach is the scalability factor. As the company grows and data science and machine learning teams become more ubiquitous, we need a more scalable model. This is where the squad framework provides an extension to the lean model by introducing the concept of tribes.
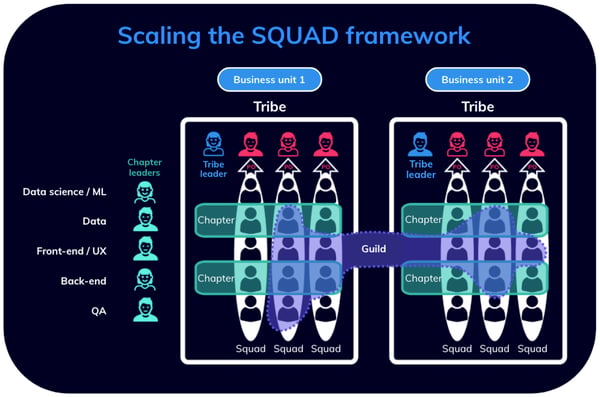
Essentially, each business unit would replicate a structure similar to a singular engineering department.
The engineering leader becomes the tribe leader and there is at least one product owner per tribe, even though they might cover multiple squads. The chapters are replicated within each business unit, each with its own members and lead.
In order to have the two tribes communicate and collaborate, guilds are incentivized. These guilds basically hold informal meetings where people in the company come together over their shared interest in a common topic, to share ideas and feedback.
When I was at Barclays, we used to gather once a month with the “Scala community,” which brought people together from very different units and functions to discuss the Scala programming language. This is a good example of what the guild structure could look like.
Follow the leader
Last, but certainly not least, I would like to talk about some diverging leadership styles to consider when filling the top role on the team.
Coercive leaders
Focus on:
- Discipline
- Policy enforcement
- Compliance
In my experience, this generally does not work out too well with the engineering and dev crowd as they value some autonomy in their work.
Transactional leaders
Focus on:
- Rewards
- Routine efficiency
- Consistent structure
This style is great for large organizations, but could run into some friction in at smaller companies that value being nimble and innovative.
Transformational leaders
Focus on:
- Optimization or "making tomorrow better"
- Invention
- Creativity
- Authenticity and transparency
- Learning from mistakes
Transformational leadership incentivizes their team to exceed expectations by means of four components:
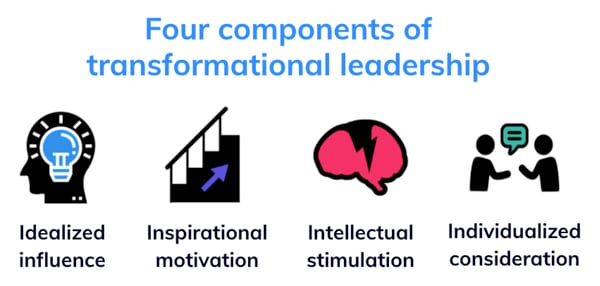
In order to understand the importance of transformational leadership for technology-driven companies, I would recommend reading Maren Fox’s article: Examining the Leadership Style of Microsoft CEO, Satya Nadella.
Ultimately, as a leader you want to make sure you foster the right data and machine learning culture in your organization via core company values such as:
- Management transparency
- Trust in the data and people
- Measurement and assessment of results
- Culture of listening and sharing
- Individual empowerment
In a quickly evolving field like machine learning, striking the right balance on your team and cultivating an environment of constant learning and growth can make all the difference for your team to produce tangible results — now and in the long run.
 Gianmario is the Chief Scientist and Head of AI at Helixa. His experience covers a diverse portfolio of machine learning algorithms and data products across different industries. He is also co-author of the book "Python Deep Learning", contributor to the "Professional Manifesto for Data Science", and founder of the DataScienceMilan.org community. Read more of his work at Vademecum of Practical Data Science.
Gianmario is the Chief Scientist and Head of AI at Helixa. His experience covers a diverse portfolio of machine learning algorithms and data products across different industries. He is also co-author of the book "Python Deep Learning", contributor to the "Professional Manifesto for Data Science", and founder of the DataScienceMilan.org community. Read more of his work at Vademecum of Practical Data Science.
