


As the possibilities of machine learning expand each year and continue to make headlines, more and more managers aspire to implement the technology in their own organizations.
To help get you started, I lay out five sequential steps that demystify the process of machine learning implementation. More importantly, these steps help determine whether this technology is an appropriate solution for your specific business needs.
The framework is battle-tested and informed by many different industries and applications, and I believe it can help provide the structure and efficiency needed as you dip your toes into the world of machine learning.
The process of effective machine learning implementation can be broken down into five core stages:
- Understanding machine learning technology
- Preparing the foundation
- Implementing baseline solutions
- Applying existing technology in new ways
- Exploring bespoke algorithms
1. Understanding machine learning technology
Back to basics
Once you’ve made the decision to enter the complex world of machine learning, it’s time to get yourself up to speed.
It’s important that you can at least nail the basics, in order to manage the implementation effectively. Luckily, the available machine learning resources are no longer limited to technicians.
The most popular online courses can be found on Coursera, Udacity, Fast.ai, and Udemy.
O’Reilly, Packt, and Manning provide any possible offering of book contents as well as video-lectures from many professional leaders around the World.
And if you’re looking for hands-on guidance, you can find plenty of boot camps and intensive, condensed programs such as the ones offered by Galvanize, Thinkful, and other masterclass innovation schools. There’s also always incredible sessions at conferences like O’Reilly, ICML, KDD, and NeurIPS.
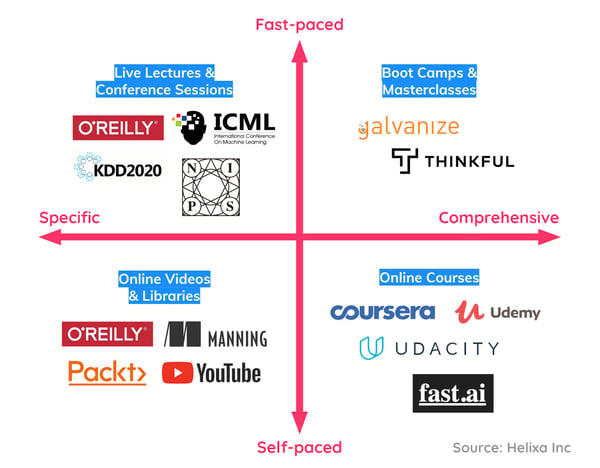
Connecting academic courses to enterprise realities
If you are new to machine learning, you will find a lot of value in those courses. But most of them share one major flaw.
The expectations of machine learning laid out in many of these academic courses are often mismatched with how the technology would actually be implemented by enterprise companies.
That’s because the academic approach simply has different goals and realities.
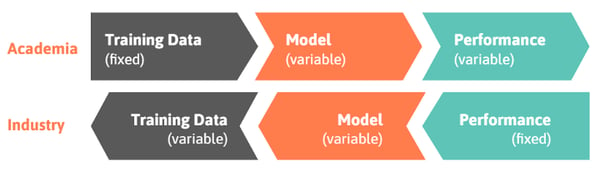
In a typical academic setting, you start with the available data and try to extract what you can out of it. Often, there is a deliberate choice to avoid the better, larger, more realistic dataset, in order to compare different research papers against the same benchmark.
This is one of the reasons you often see papers and tutorials referring to the same datasets, which include MNIST, ImageNet, COCO, WMT 2011 NewsCrawl, and MovieLens.
Beginning with the end in mind
Put simply, the standard goal of academics is to beat the benchmark, even if by a small percentage of the baseline metric.
In enterprise companies, that process is reversed.
Industry professionals start by framing the desired outcome and working their way backward to fulfill the requisites. They investigate which model and data will check all the boxes, keeping the end-goal in mind at every step.
 SOURCE: KDnuggets
SOURCE: KDnuggets
Often this backward process forces development teams to think outside the box and invent unconventional solutions that are specific to the business case at hand.
Where different methods and tools would be isolated for study in academia, they instead come together in enterprise settings for an ensemble that is greater than its parts.
2. Preparing the foundation for machine learning
So now you’ve taken a few courses and have a working knowledge of machine learning basics. You’re probably itching to schedule a kickoff meeting and start building your machine learning offerings.
But first, you need the right foundation. Otherwise, everything you build will collapse in on itself.
There are three sequential stages of maturity that any enterprise company needs to go through before considering machine learning implementation.
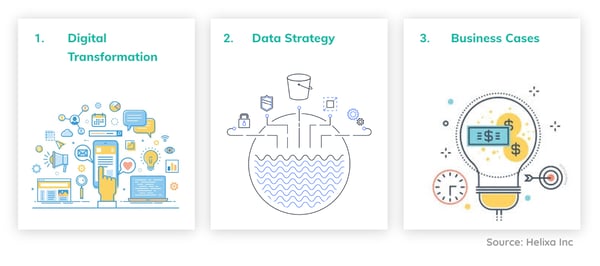
Digital transformation
Before you can even consider developing machine learning capabilities, you need to ensure that your business has a digital mindset.
The business processes, products, and customer experience all need to reflect that focus. More importantly, so does the company culture.
Without full organizational buy-in, the next steps are nearly impossible.
This obstacle is usually the realm of legacy companies and managers who default to familiar, but outdated processes. If your executives are still relying on printouts of digital dashboards in meetings, you have internal work to do before moving on.
Data strategy
Most technology-focused companies were founded on those digital-first principles, but that doesn’t automatically mean they have the infrastructure in place to support a cohesive data strategy.
It’s important to create a strong data fabric — an ecosystem that provides seamless, well-governed data integration across various systems within the enterprise. As part of this, you need to map out potential interactions with trusted external data providers and marketplaces.
Most of the inefficiencies in data science teams originate from the lack of proper infrastructure and data availability. I have personally seen projects fail from chasing lofty ambitions within companies and markets that were simply not prepared.
Therefore, even if you already have systems in place, now is a good time to review the existing data fabric to ensure it can support your machine learning ambitions. A culture of data-driven decisions and experiments will help increase your chances of success.
As part of this, I want to also add that you need to build trust in the data and the people who work with it to succeed in this stage. Those are the two pillars of enabling data-driven decisions.
Business cases
Once that is all in place, you need to ensure that you even have an argument for machine learning at your specific organization.
Usually, companies who are successful at implementing machine learning have a few things in place before starting:
- Existing data-driven products or services
- A clear business strategy (that doesn’t rely on machine learning yet)
- Established domain knowledge and customer relationships
- Sufficient funding for machine learning investment
Once those prerequisites are in place, it’s time to determine whether the business cases are compatible with what is solvable by machine learning technology.
Though the technology is impressive, some things remain impossible, like predicting the outcome of the Kentucky Derby using a horse's eye color or predicting future stock prices accurately using publicly available data.
Here's a common-sense rule of thumb: If there is a dataset we can reasonably collect that contains enough signal for a domain expert to find the required answers, machine learning could be a good way to speed up the process and bring it to scale.
For further vetting, ask the following questions:
- Is it possible to build a proof-of-concept in a few weeks?
- Have other people already solved a similar task?
- Have we already collected some initial dataset related to the task we want to solve?
- Can we automate some repetitive process carried out by humans only?
- Can we improve the accuracy, robustness, and maintainability of tasks currently solved with software rules?
Stability requires patience
Companies should plan and execute the above three stages of maturity in a coordinated and consistent way, iterating many times to reach a stable technology ecosystem. That stability will bear better fruit when it comes time to introduce the machine learning implementation.
While it may be tempting to implement these stages simultaneously, that is a common mistake that often leads to many unstructured, and ultimately failed attempts.
Even if a few technology companies have pulled it off, I wouldn’t suggest playing those odds.
3. Implementing baseline machine learning solutions
Don’t reinvent the wheel… yet
When you are finally ready to implement machine learning solutions for your enterprise company, it can be hard deciding where to start.
Even within your niche of your industry, machine learning processes can probably be applied to many different business problems.
That’s why the general consensus is usually to start with low-hanging fruit. Don’t be afraid of implementing a baseline solution made of only if-else rules and simple counts and divisions.
By starting with tasks that have simple solutions with quick wins, you increase the chances that your early efforts will be rewarded. That success will also build confidence among your team and important internal stakeholders.
Fit the tool to the job
When you’re solving problems for a paying customer, you need to use the best tool at your disposal. It doesn’t matter if it’s an old-fashioned statistical model or the hottest new algorithm.
For example, traditional tasks are better solved with traditional statistics like the ones described below.
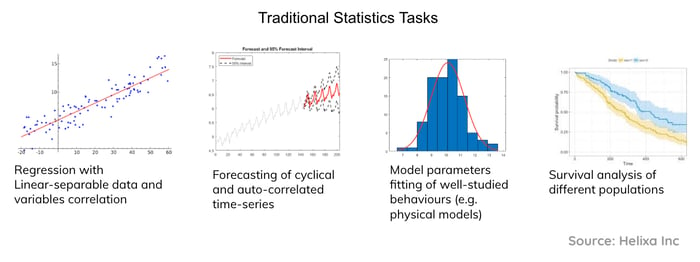
Machine learning, on the other hand, really shines when dealing with complex cognitive tasks or large, multi-dimensional, unstructured datasets.
After we have implemented the first baselines, there will be a time where advanced machine learning solutions will be required.
But how do you know when that time has come?
Where machine learning excels
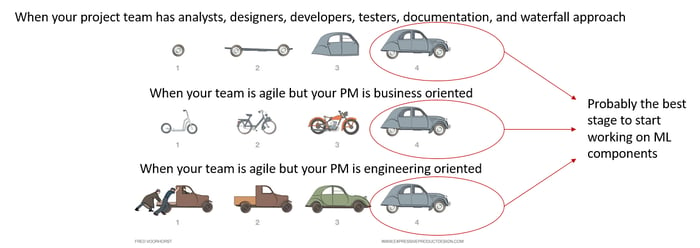
The implementation usually fits best in the period after the first prototype is developed, to scale a process that previously involved manual effort from members of your team.
Ultimately, machine learning components are merely key-enablers for some product, feature, or service. Their value is measured in the context of the solutions they power.
While we can observe some similarities between standard, data-driven software and software enabled by machine learning — also called Software 2.0 — the latter simply presents different core challenges.
In Software 2.0, the behavior is not deterministic. Also, the implementation forces us to deal with open problems and accuracy requirements.
Machine learning can be seen as the meta-learning part of modern software. After taking in training data and a definition of the desired behavior, machine learning returns data-driven software as an output, which can then be used to process inference data.
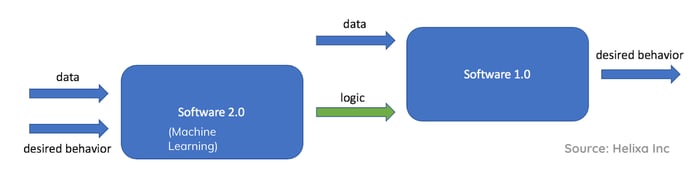
Essentially, machine learning is needed every time decision logic is difficult for humans to code but relatively easy for machines to learn. That’s why it’s best tackled after the initial prototype is successfully implemented.
SOURCE: yzico.engineering
4. Applying existing state-of-the-art technology in new ways
For many companies in the “hardcore machine learning” space, innovation stems from the application of existing technology to specific use-cases, based on the business problems they are looking to solve.
That’s the topic of an article that’s always suggested to companies developing machine learning offerings: “Why businesses fail at machine learning” by Cassie Kozyrkov, Chief Decision Intelligence Engineer at Google.
In a few words, she says that if the goal of your business is to sell products powered by machine learning, you should take all that you can from existing literature and apply it without rebuilding from scratch.
She uses the analogy of a bakery — why build your own oven when you can focus on making great bread with the best oven you can find?

SOURCE: Hacker Noon
In these cases, research is “limited” to experimentation around the ways the current state-of-the-art application fits into the organization to generate value. We refer to this field as “applied machine learning” as opposed to pure “machine learning research”. This has several implications in terms of skill sets and hiring.
Thus, my recommendation is threefold: Start from places like PapersWithCode.com, use off-the-shelf libraries extensively, and leverage cloud services.

5. Exploring bespoke machine learning algorithms
There are cases, though, where even the most state-of-the-art approach to existing technology doesn’t solve the problem at hand.
That’s when we start really getting into uncharted territory.
While implementing bespoke algorithms brings its own advantages, you should be aware of the challenges, the additional level of complexity, and the associated risk.
For efficient and scalable implementations, bespoke machine learning algorithms require both a strong theoretical background and robust coding skills.

To give you an example, at Helixa we built a novel approach for merging datasets from different domains called “Audience Projection”.
It was very exciting to work on a novel solution to the cross-domain adaptation problem. Plus, the challenges and risks were justified by the competitive edge we gain through our proprietary methodology.
In that case, we are talking about the team of an AI startup, whose value is rooted in our intellectual property (IP) in addition to the value generated for our customers.
For tech companies with ML at their core, it does make sense to invest in bespoke algorithms and novel solutions. Especially if their future potential application can be generalized beyond the current products and market segment.
--------------

Download Our Machine Learning Guide
The thought of getting started with machine learning can be paralyzing. There are a million different things to consider and just as many ways to get it wrong.
To help you nail it the first time, our Chief Data Scientist captured all of his hard-won lessons from the past 10 years and poured them into our brand new, non-technical machine learning guide for managers.

 Gianmario is the Chief Scientist and Head of AI at Helixa. His experience covers a diverse portfolio of machine learning algorithms and data products across different industries. He is also co-author of the book "Python Deep Learning", contributor to the "Professional Manifesto for Data Science", and founder of the DataScienceMilan.org community. Read more of his work at Vademecum of Practical Data Science.
Gianmario is the Chief Scientist and Head of AI at Helixa. His experience covers a diverse portfolio of machine learning algorithms and data products across different industries. He is also co-author of the book "Python Deep Learning", contributor to the "Professional Manifesto for Data Science", and founder of the DataScienceMilan.org community. Read more of his work at Vademecum of Practical Data Science.
