


We’re reaching a tipping point in the field of enterprise AI and machine learning.
According to a recent study by Dresner, 33% of interviewed enterprise companies have already adopted AI and machine learning technologies. And as the industry evolves, the rest will eventually have to make serious investments in this area.
In my previous introduction to this topic, I laid out the initial steps for enterprise companies looking to investigate the potential of machine learning for their organizations. If you are reading this, I’m assuming that you have weighed your options and made the choice to adopt this exciting technology.
But even if machine learning is a perfect fit for your business, the value it brings is largely dictated by the choice of products and services that are offered.
Let’s review some practices and techniques to make sure you get it right.
Developing a machine learning strategy
In any innovative company, the definition of a product feature or service comes from the top down. That process is guided by the company’s strategic objectives, as laid out by the founders, CEO, board, and top executives.
The process for machine learning adoption, like any other process, is built on the foundation provided by the company’s mission statement. That statement lays out what the company is, why it exists, and its reason for existing.
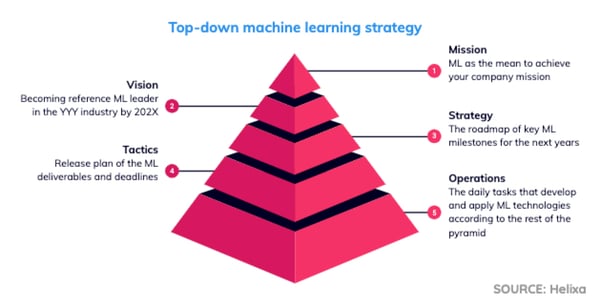
Then, it’s critical to align with the shared vision of the company’s direction — usually a timeline between one and three years for most startups.
Once that is established, it’s time to develop a long-term strategy for how the company will achieve that goal.
Strategy reflects the core values of the company and guides future decision-making. But, to do that, it must be actionable. Short-term tactics and daily operational actions are necessary to implement that strategy and keep it on track.
Machine learning can fit any level of the pyramid, depending on the nature of the organization and how crucial the technology is for its future.
Case study: Helixa
If we analyze our machine learning strategy at Helixa, we can identify how machine learning technology shows up at each level of our pyramid:
- Mission: Connect brands and marketers with relevant consumer audiences through ethical and intentional machine learning.
- Vision: Position ourselves as the market research thought leader in the world of machine learning.
- Strategy: Partner with gold-standard research companies, in order to augment their consumption research studies with online behavioral data.
- Tactics: Implement forward-thinking projects, such as our proprietary Audience Projection framework, to merge different anonymous datasets in a federated learning fashion.

The impossible trinity of machine learning constraints
As a product manager or other decision-maker, you need to understand that there is no “free lunch” in product development. Pushing the development team too hard might elicit quicker results, but at the expense of quality and operational efficiency.
On the other hand, if you leave the deadline open-ended, it’s likely the product would enter the market too late and miss important opportunities.
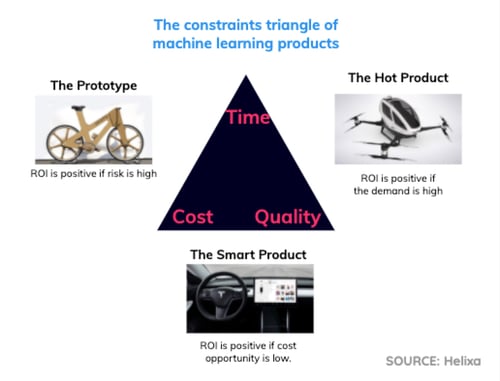
Think of the three major constraints — time, cost, and quality — as a framework for understanding what is possible with machine learning development. You can attempt to do it in a way that is fast, cost-efficient, and high-quality, but only two can be realistically achieved.
There are different pros and cons for each pairing. Here are the three archetypes that emerge.
The Prototype (fast + cost-efficient)
- Quick-and-dirty implementation
- Baseline accuracy
- Many technical debts
- Manually annotated data on a smaller data sample
- Manual processing likely required
- Acceptable for proof-of-concept
ROI is positive if... the risk of missing the market fit is high and we can accept low performances to validate the right fit.
The Hot Product (fast + high-quality)
- Exploits expensive off-the-shelf services
- Brute force model selection or AutoML services
- Black-box approach
- Non-optimized code, wasting resources
- Acceptable short-term solution
ROI is positive if… the demand is certain to be very high and revenue is guaranteed.
The Smart Product (high-quality + cost-efficient)
Deeper analysis on problem, data and model behavior.
- State-of-the-art implementation using open-source.
- High attention to design and details.
- Long-term durable solution.
- Focus on stability and scalability.
ROI is positive if… the cost opportunity is low and the company can afford to bet on a single product at the cost of missing new market opportunities.
Customer discovery answers the hard questions
Once we have defined what the budget and expectations are, we want to answer two questions:
- Are we solving a real problem?
- Will enough customers pay us for the solution?
The basic techniques of customer discovery for tangible goods can also be applied to digital products, including buyer personas, customer journeys, interviews, and focus groups.
If the product is meant to launch a new business from scratch, or if the business model is not yet scalable and profitable, I would recommend creating a business model canvas from these insights. There is also a simplified lean model canvas for innovative startups that focus specifically on a single product and less on the overall business.
Requirements: functional vs. non-functional
Although every product and market segment is significantly different from the next, we can identify a common set of requirements for machine learning features.
In particular, let’s focus on non-conventional requirements that you generally wouldn’t find in traditional software products.
Functional requirements:
- Input: What features go in?
- Output: What predictions come out?
- Environments: How is it integrated with the rest of the system during both training and inference stages?
- Explainability: What motivated the provided predictions?
- Interpretability: What are confidence intervals of the predictions?
A common mistake is to deprioritize or simply ignore interpretability.
Unlike traditional software, the behavior of machine learning components is uncertain. Every output should be interpreted in terms of confidence intervals, whether we are estimating numerical quantities, engaging in time-series forecasting, or using single probability scores.
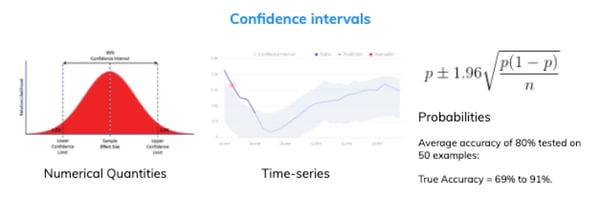
When using machine learning outputs to make decisions, it is fundamental that the system provides a friendly way to interpret them.
Decision-makers must also understand basic statistical significance, so it is no wonder that most current MBA programs include concentrations in statistics and data-driven decision making.
Non-functional requirements:
- Accuracy performance: Is the accuracy above the minimum acceptable level?
- Data quality: Does the input data contain enough signal to solve our problem?
- Scalability: How many users/predictions can be served, per unit of time?
- Response time/availability: Are features always available for inference?
- Stability: Is the model providing consistent predictions all the time?
- Maintainability: Is the model easily fine-tuned and updated?
Data quality is another requirement that is often hard to grasp.
Many executives seem to think that data scientists and engineers are magicians who can extract any signal out of messy data, and the reality can often cause disappointment.

SOURCE: XKCD
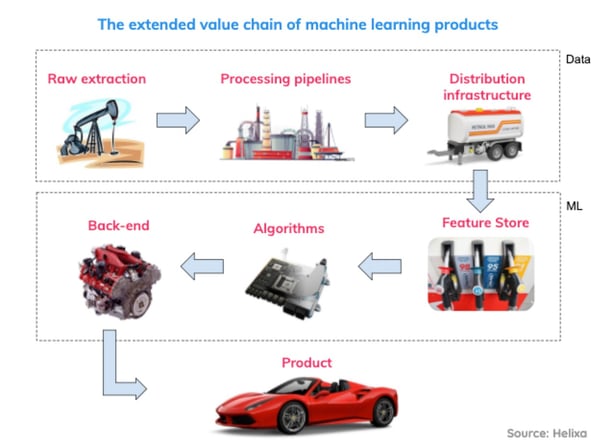
If you sacrifice data quality, the performance of the product will suffer throughout the entire “extended value chain,” including the raw data extraction process, multiple processing stages in between, and even the algorithms’ ability to crunch the processed data.
Building your toy product
At this point in the process, you should have the first draft of the product requirements you want to implement.
Before committing to a long-term development plan, you need to find out if your assumptions hold and align with your customers’ needs. Ideally, you’ll want to figure this out as early as possible.
Maintain momentum by getting to “good enough”
The agile manifesto prioritizes “working software over comprehensive documentation” and asserts “the best architectures, requirements, and designs emerge from self-organizing teams.” However, it does not provide a framework for keeping everybody on the same page with many actors involved (e.g. multiple dev teams, product managers, customers, executive stakeholders).
Getting a simple and working application into their hands would be the best way to collect feedback. But, unfortunately for us, machine learning projects can rarely be delivered in a sprint’s worth of work.
Also, the way enterprise companies tend to define their minimum viable products (MVPs) is often far from what would be commonly considered the “minimum.”
To understand why, let’s consider an established company with a renowned reputation and high-paying customers. No executive would risk delivering a poor product with the promise of enriching it at a later date. In the case of machine learning products, this scenario would be even worse, because models may require a priori unknown amount of work to achieve stable and accurate predictions.
With that in mind, how do we validate the product we want to build, ahead of time, so we can pivot if necessary?
Show, don’t tell
From my experience, it is very effective to iterate repeatedly through the customer discovery process using incremental proof-of-concept artifacts. Wireframes and mockups are an excellent place to start this process and validate the design of your user experience (UX) and possibly the user interface (UI).
If your company is delivering an analytics product, you may want to provide data and charts as part of the mock-up. I find it helpful to build toy products with a sample of realistic data and simulate the machine learning models with static predictions.
You can start a simple dashboard in your preferred spreadsheet software and have it finished by your afternoon espresso the same day, with preliminary interactive plots. And if you need something fancier and closer to the functional requirements, I recommend checking out Dash by Plotly or a similar programmatic framework.

At Helixa, we use those dashboard frameworks to quickly build proof-of-concept apps before committing to expensive production systems. This allows the data science team to build its own web apps at a higher level of complexity, without tapping the web development team for ad-hoc solutions
But the value doesn’t stop there. Product managers and customer-facing staff can also use these apps to demo the product and collect feedback. (Don’t forget to get a few members of the product team involved in that customer feedback loop.)
Get everyone on the same page with information flows
By this point, we have validated or adjusted assumptions about our potential customers.
But what about alignment among dev teams and internal stakeholders? After all, i’s possible the dev team could build an “incompatible” product, and that risk only goes up when implementation details are more strongly impacted by algorithmic methodology.
The key is formalizing requirements in a visual way and documenting them. Instead of relying on long, written statements that are only legible (and interesting...) to the person who wrote them, these visual documents explain the methodologies in a digestible deck format.
I like to refer to them as “information flows.”
When you scroll through an information flow, you can quickly understand the main requirements and explanations of the machine learning development, because the format is simpler and more engaging.
This allows anybody in the organization — sales, customer support, marketing, HR — to understand how the underlying system works, without wading through pages of technical jargon.
And that’s a huge step toward getting everyone on the same page, so you can move forward together.
--------------

Download Our Machine Learning Guide
The thought of getting started with machine learning can be paralyzing. There are a million different things to consider and just as many ways to get it wrong.
To help you nail it the first time, our Chief Data Scientist captured all of his hard-won lessons from the past 10 years and poured them into our brand new, non-technical machine learning guide for managers.

 Gianmario is the Chief Scientist and Head of AI at Helixa. His experience covers a diverse portfolio of machine learning algorithms and data products across different industries. He is also co-author of the book "Python Deep Learning", contributor to the "Professional Manifesto for Data Science", and founder of the DataScienceMilan.org community. Read more of his work at Vademecum of Practical Data Science.
Gianmario is the Chief Scientist and Head of AI at Helixa. His experience covers a diverse portfolio of machine learning algorithms and data products across different industries. He is also co-author of the book "Python Deep Learning", contributor to the "Professional Manifesto for Data Science", and founder of the DataScienceMilan.org community. Read more of his work at Vademecum of Practical Data Science.
